OpenAPI Flaws - Type and Format
How would you define a parameter/field of type “long”? It’s easy, right? You just declare the parameter/field with its type:
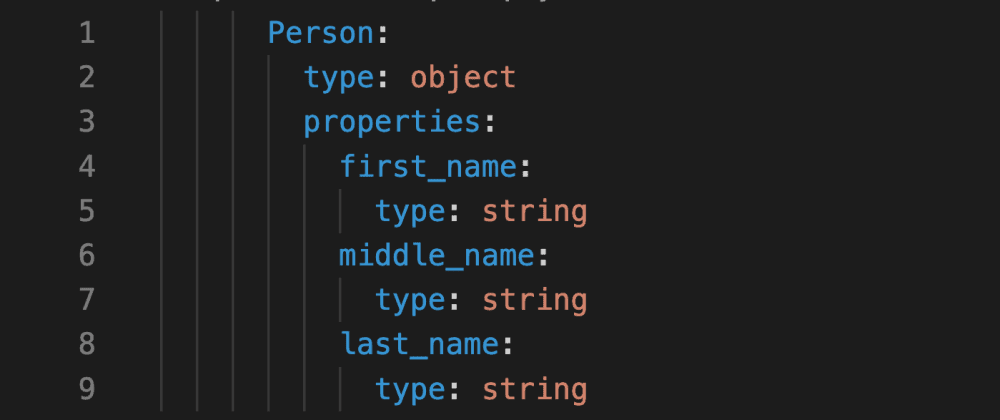
Java and C#: long the_field
Kotlin: the_field: Long
Go: int64 the_field
Rust: the_field: i64
Every programming language has an "optimized" way of coding parameters/fields. This is understandable and expected since writing code consists majorly of defining fields and function parameters.
Format
Now, how would you do it in OpenAPI and JSON Schema? It must be easy given that long is pretty widely used, right?
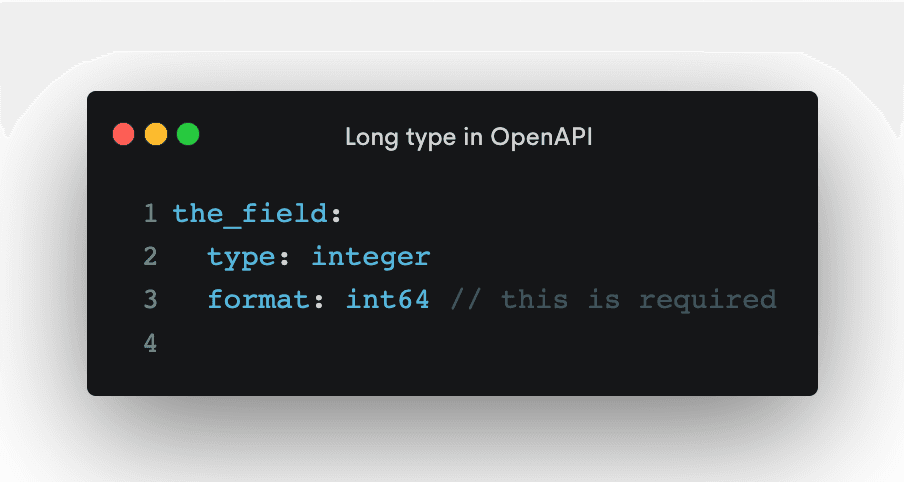
You would need the format field:
the_field:
type: integer
format: int64
Why do we need two fields: type and format? Why can't we just put type: int64? The type int64 is not among the supported types by OpenAPI and JSON Schema: string, number, integer, object, array, boolean, null. All other types should use the format for clarification.
One might note that such a limited type system is inherited after JSON itself. Meaning that OpenAPI and JSON Schema are designed to schematize only those types that might be met in JSON. However, this is not true. The type integer does not exist in JSON or JavaScript, so the specification is already inventing new types. Why not invent at least all basic types, like int64? The int64 is not alone, there are other useful types.
Additionally, the same syntax of type and format fields is used in both JSON schemas and operation parameters. HTTP operation parameters definition is not under any JavaScript type system limitation. Operation parameters (query, header, form-data, cookies) should be serializable to string (or array of strings). They have nothing to do with types supported in JSON.
Here are formats mentioned in OpenAPI documentation: int32, int64, float, double, byte, binary, date, date-time, uuid.

Yes, that’s right - API specification can’t use almost any type without a format specified. The format field seems to be more useful than the type field.
Brevity
Finally, the way how OpenAPI and JSON Schema have designed built-in types forces developers to write more lines or use additional structures:
the_field1: # There are 3 lines to define the field
type: integer
format: int64
the_field2: { type: integer, format: int64 } # Additional structure
In the example above there are no required flags specified for the fields that were discussed in the previous post. Specifying required flags altogether with format makes the field even longer.
Here is a possible fix for this design:
the_field1: int64
the_field2: uuid
This would mean "the_field has int64 type" as in any normal programming language. The type above is logical. It's not just some type in the serialization protocol. The type has a bit more meaning - what is stored in that field? what kind of number it is? what kind of string it is? These are all questions that good specifications should answer. The logical type still defines the technical type of the JSON field univocally: uuid -> string, int64 -> integer, datetime -> string...
The design could be leveraged to mark fields as non-required (optional):
the_field: optional<int64>
Alternatively:
the_field: int64?
Code above uses neither type nor format nor required. We came down to the meat of the field definition without any additional things specified. This is very in line with how interfaces including fields and parameters are defined in programming languages. They are intentionally designed to use short definitions. Brevity matters for better writing and the readability of the specification.
Such quirks like format and type definitions are very strange to developers who are used to better ways of defining parameters/fields. I think overall it repels developers from working with specifications. Read about more OpenAPI specification flaws in this series.